Regression and Bootstrap Confidence Intervals#
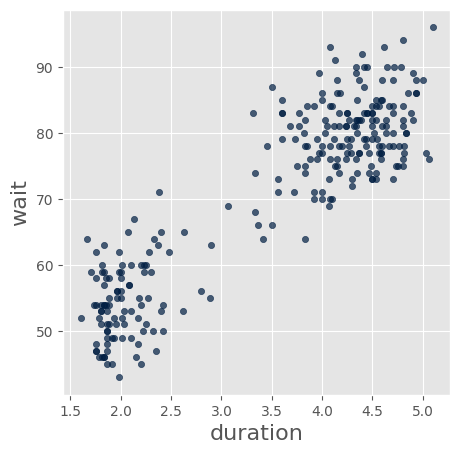
The bootstrap is a method which computes a statistic of a dataset and the uncertainty in the population statistic by using repeated sampling with replacement of a data set. We can use the datascience table .sample() method to carry out re-sampling of a table with replacement. What does this mean in practice? It meeans that some of the rows of data may appear twice or more in the re-sampled data and other will be omitted leaving the same number of data points (rows) but, importantly, a new estimate of the statistic. This is demonstrated below with the Old Faithful data investigating the relationship between eruption duration (minutes) and the wait time (minutes) until the next eruption.
from IPython.display import YouTubeVideo
YouTubeVideo("wE8NDuzt8eg")
Old Faithful#
Use Bootstrap sampling to estimate 95% confidence interval on our estimated slope.
faithful = Table.read_table("data/faithful-new.csv")
faithful.scatter('duration','wait')
Regression Tools#
def standard_units(xyz):
"Convert any array of numbers to standard units."
return (xyz - np.mean(xyz))/np.std(xyz)
def correlation(t, label_x, label_y):
return np.mean(standard_units(t.column(label_x))*standard_units(t.column(label_y)))
# Regression
def slope(t, label_x, label_y):
r = correlation(t, label_x, label_y)
return r*np.std(t.column(label_y))/np.std(t.column(label_x))
def intercept(t, label_x, label_y):
return np.mean(t.column(label_y)) - slope(t, label_x, label_y)*np.mean(t.column(label_x))
Sample the faithful Table#
sfaithful = faithful.sample() # Try 20 samples
sfaithful.scatter('duration','wait')
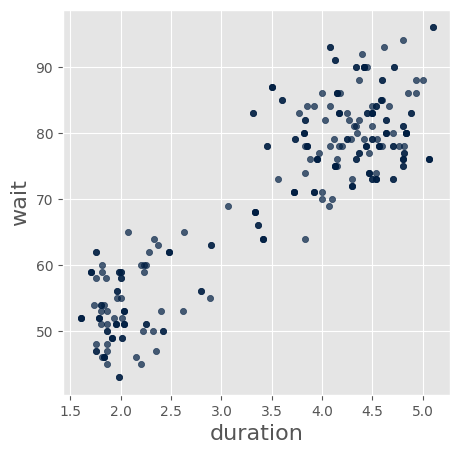
sfaithful = faithful.sample() # Resample the whole Table with replacement
sfaithful.scatter('duration','wait')
slp = slope(sfaithful, 'duration','wait')
inter = intercept(sfaithful,'duration','wait')
print("Slope: %4.2f Intercept: %4.2f" % (slp, inter))
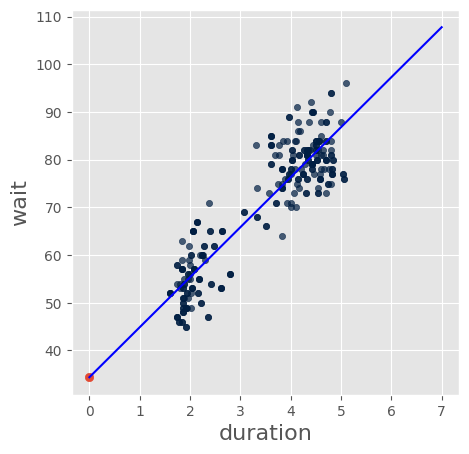
plt.scatter(0,inter)
xs = [0, 7]
ys = [inter, slp * 7 + inter]
plt.plot(xs,ys, color='blue')
plt.show()
Slope: 10.49 Intercept: 34.38
slp = slope(faithful.sample(), 'duration','wait')
print(slp)
10.447625481
sample_slope = []
for i in np.arange(10000):
slp = slope(faithful.sample(), 'duration','wait')
sample_slope.append(slp)
left = percentile(2.5, sample_slope)
right = percentile(97.5, sample_slope)
make_array(left, right)
array([ 10.15073231, 11.31667109])
slope(faithful, 'duration','wait')
10.729641395133529
Confidence Interval (95%)#
CI = (right - left)/2
CI
0.58296939013378601
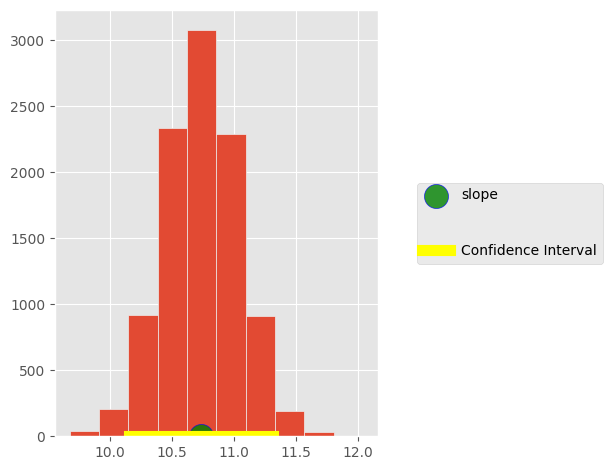
95% Confidence Interval on slope: 10.3 +/- 0.6
plt.hist(sample_slope)
plt.scatter(10.73,0, s=300, label='slope',marker='o',
c='green',alpha=0.8, edgecolors='blue')
plt.plot([left, right], [0, 0], color='yellow', lw=8, label='Confidence Interval')
plt.legend(loc='center left', bbox_to_anchor=(1.1, 0.5), labelspacing=3)
plt.tight_layout()
sample_intercept = []
for i in np.arange(10000):
inter = intercept(faithful.sample(), 'duration','wait')
sample_intercept.append(inter)
left = percentile(2.5, sample_intercept)
right = percentile(97.5, sample_intercept)
make_array(left, right)
array([ 31.31362752, 35.65717206])
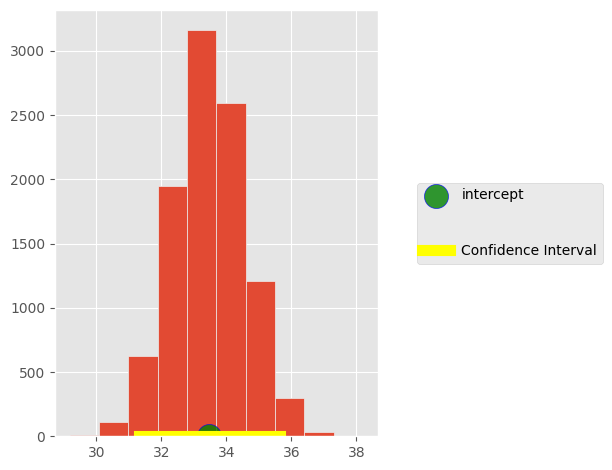
plt.hist(sample_intercept)
plt.scatter(33.47,0, s=300, label='intercept',marker='o',
c='green',alpha=0.8, edgecolors='blue')
plt.plot([left, right], [0, 0], color='yellow', lw=8, label='Confidence Interval')
plt.legend(loc='center left', bbox_to_anchor=(1.1, 0.5), labelspacing=3)
plt.tight_layout()
np.mean(faithful['duration'])
3.4877830882352936